
Projects

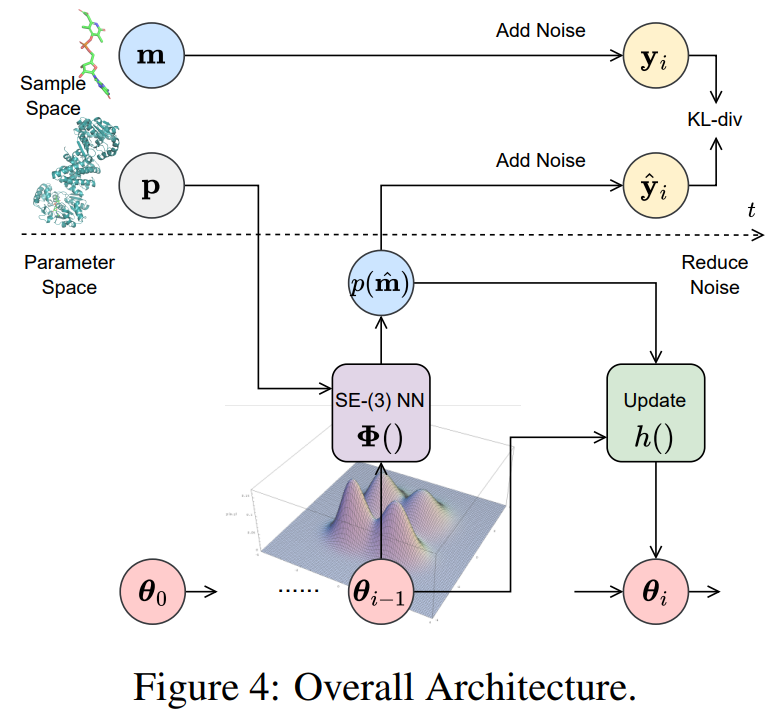
Generative Modeling of Scientific Data
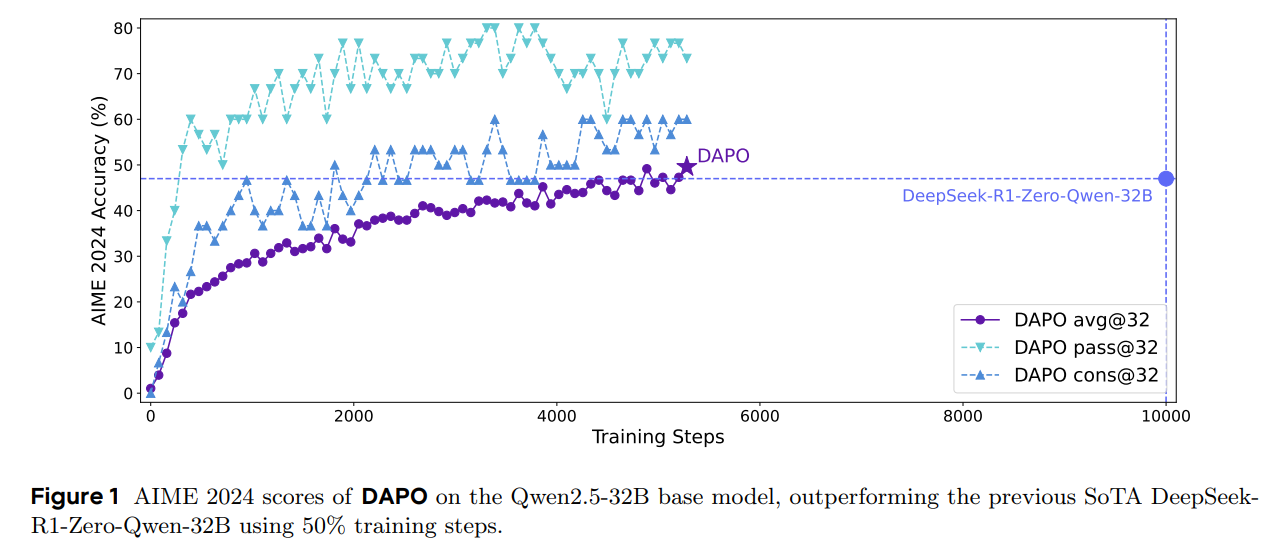
Large Language Model
Foundation Models of AI4S
Publications
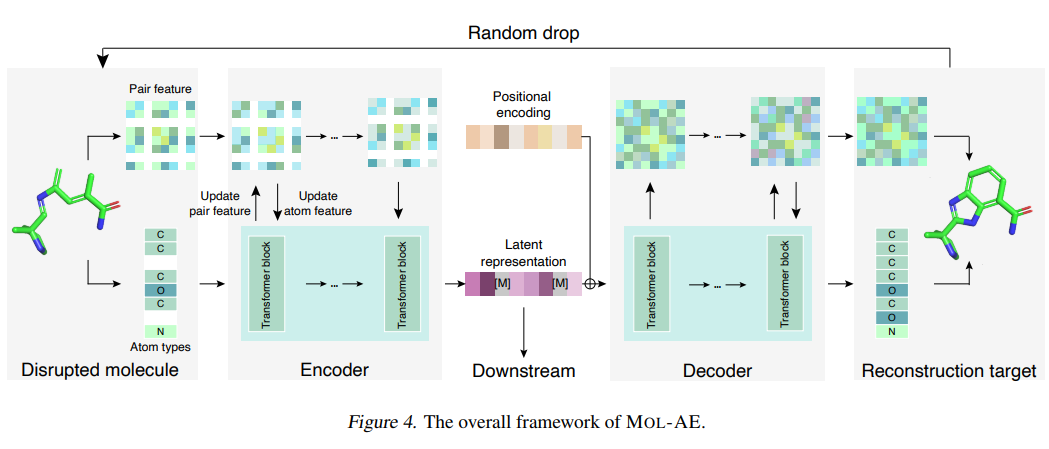
Mol-AE: Auto-Encoder Based Molecular Representation Learning With 3D Cloze Test Objective
3D molecular representation learning has gained tremendous interest and achieved promising performance in various downstream tasks. A series of recent approaches follow a prevalent framework: an encoder-only model coupled with a coordinate denoising objective.
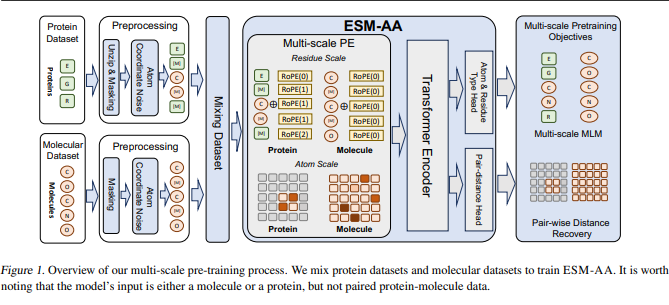
ESM All-Atom: Multi-scale Protein Language Model for Unified Molecular Modeling
Protein language models have demonstrated significant potential in the field of protein engineering. However, current protein language models primarily operate at the residue scale, which limits their ability to provide information at the atom level.
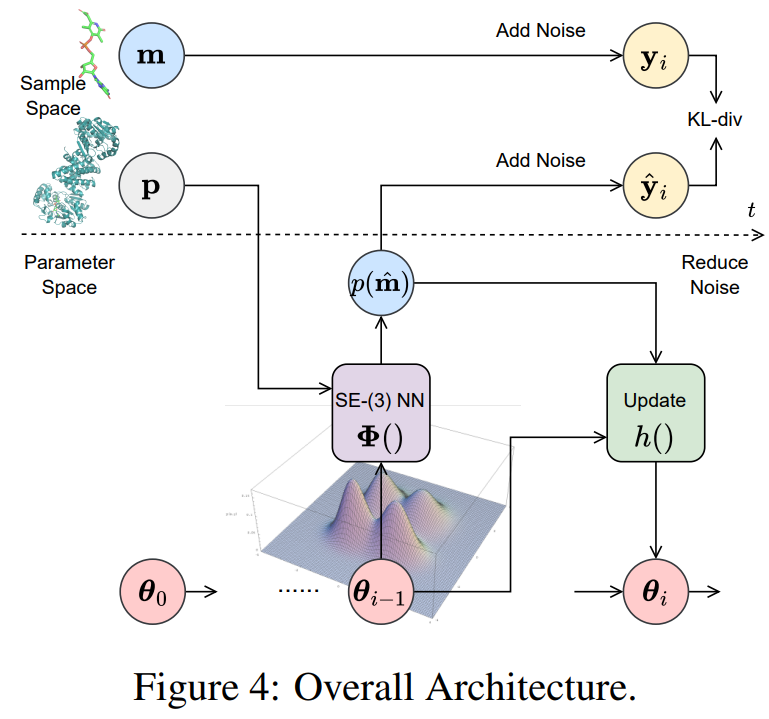
MolCRAFT: Structure-Based Drug Design in Continuous Parameter Space
Generative models for structure-based drug design (SBDD) have shown promising results in recent years. Existing works mainly focus on how to generate molecules with higher binding affinity, ignoring the feasibility prerequisites for generated 3D poses and resulting in false positives.
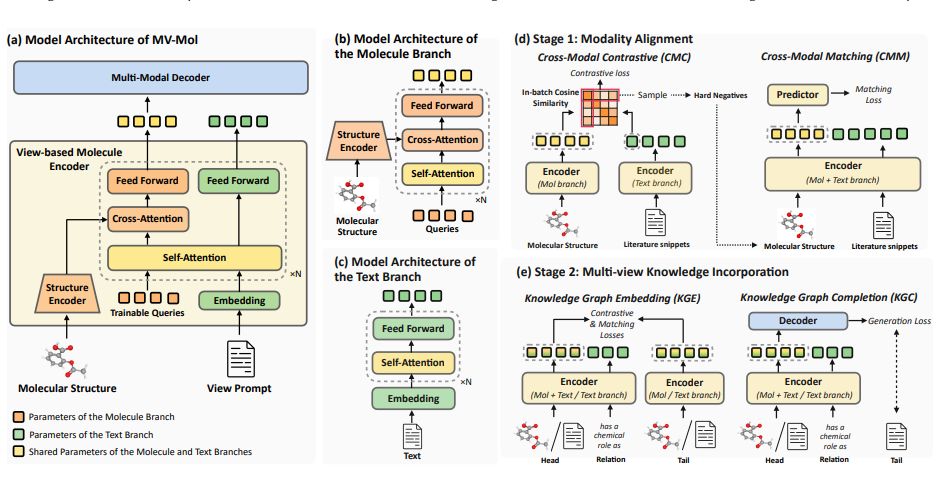
Learning Multi-view Molecular Representations with Structured and Unstructured Knowledge
Molecular representation learning bears promise in vast scientific domains. Capturing molecular expertise based on diverse views is of great significance in learning effective and generalizable molecular representations.
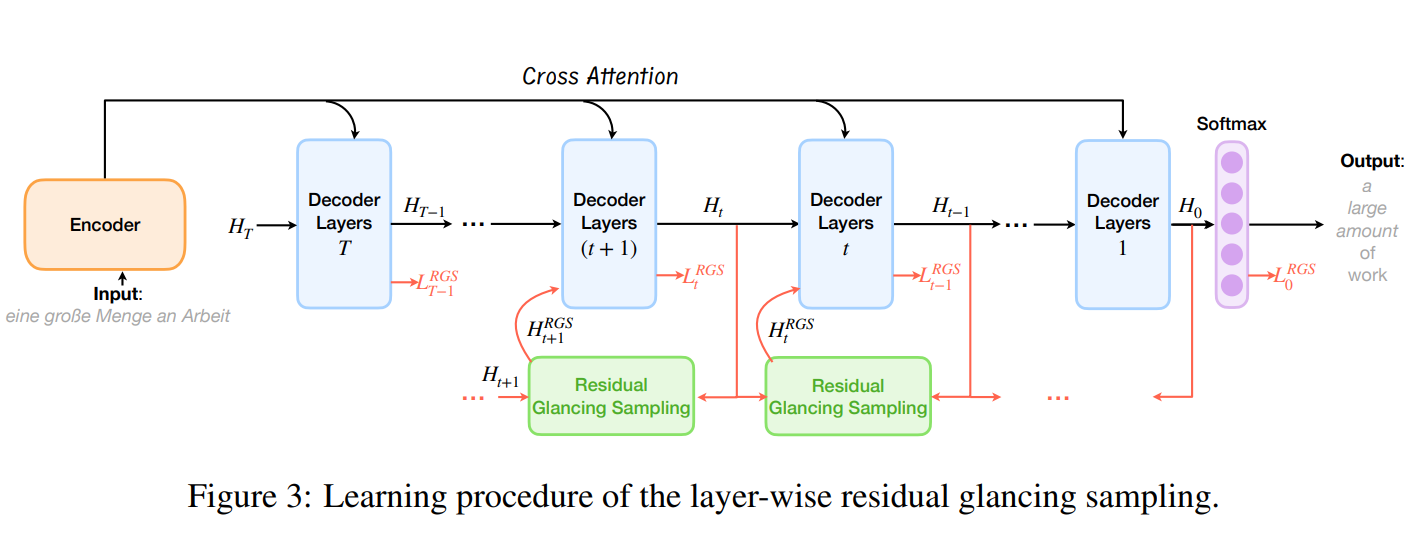
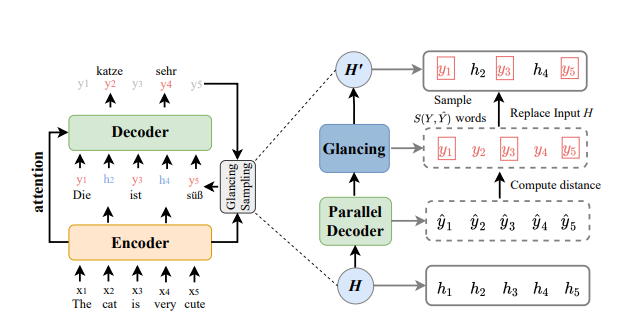
Diffusion Glancing Transformer for Parallel Sequence-to-Sequence Learning
Previously, non-autoregressive models were widely recognized as being superior in generation efficiency but inferior in generation quality due to the challenges of modeling multiple target modalities. To enhance the multi-modality modeling ability, we propose the diffusion glancing transformer, which employs a modality diffusion process and residual glancing sampling.
SHOW ALL
Mol-AE: Auto-Encoder Based Molecular Representation Learning With 3D Cloze Test Objective
3D molecular representation learning has gained tremendous interest and achieved promising performance in various downstream tasks. A series of recent approaches follow a prevalent framework: an encoder-only model coupled with a coordinate denoising objective.
ESM All-Atom: Multi-scale Protein Language Model for Unified Molecular Modeling
Protein language models have demonstrated significant potential in the field of protein engineering. However, current protein language models primarily operate at the residue scale, which limits their ability to provide information at the atom level.
MolCRAFT: Structure-Based Drug Design in Continuous Parameter Space
Generative models for structure-based drug design (SBDD) have shown promising results in recent years. Existing works mainly focus on how to generate molecules with higher binding affinity, ignoring the feasibility prerequisites for generated 3D poses and resulting in false positives.
Learning Multi-view Molecular Representations with Structured and Unstructured Knowledge
Molecular representation learning bears promise in vast scientific domains. Capturing molecular expertise based on diverse views is of great significance in learning effective and generalizable molecular representations.
Diffusion Glancing Transformer for Parallel Sequence-to-Sequence Learning
Previously, non-autoregressive models were widely recognized as being superior in generation efficiency but inferior in generation quality due to the challenges of modeling multiple target modalities. To enhance the multi-modality modeling ability, we propose the diffusion glancing transformer, which employs a modality diffusion process and residual glancing sampling.
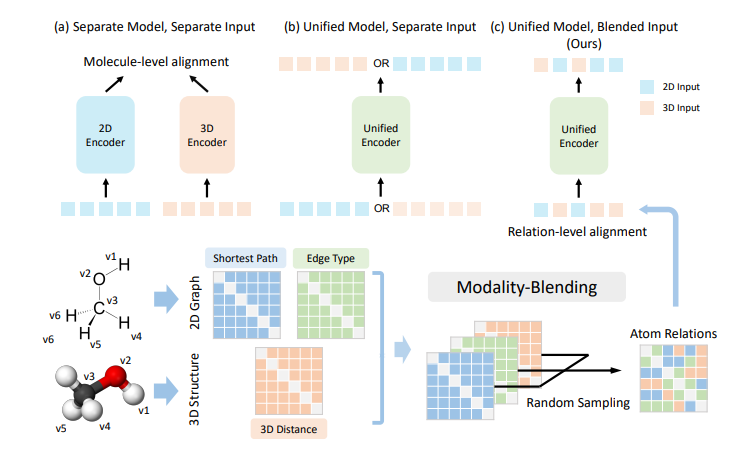
Multimodal Molecular Pretraining via Modality Blending
Self-supervised learning has recently gained growing interest in molecular modeling for scientific tasks such as AI-assisted drug discovery. Current studies consider leveraging both 2D and 3D molecular structures for representation learning.
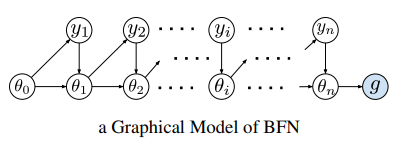
Unified Generative Modeling of 3D Molecules with Bayesian Flow Networks
Advanced generative model (e.g., diffusion model) derived from simplified continuity assumptions of data distribution, though showing promising progress, has been difficult to apply directly to geometry generation applications due to the multi-modality and noise-sensitive nature of molecule geometry. This work introduces Geometric Bayesian Flow Networks (GeoBFN), which naturally fits molecule geometry by modeling diverse modalities in the differentiable parameter space of distributions.
Equivariant Flow Matching with Hybrid Probability Transport for 3D Molecule Generation
The generation of 3D molecules requires simultaneously deciding the categorical features~(atom types) and continuous features~(atom coordinates). Deep generative models, especially Diffusion Models (DMs), have demonstrated effectiveness in generating feature-rich geometries.
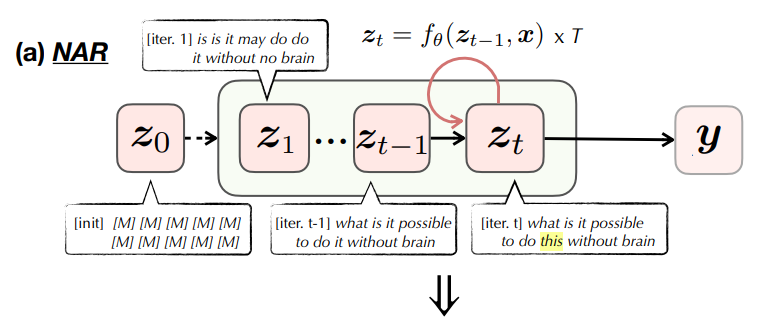
Deep Equilibrium Non-autoregressive Sequence Learning
In this work, we argue that non-autoregressive (NAR) sequence generative models can equivalently be regarded as an iterative refinement process towards the target sequence, implying an underlying dynamical system of NAR model: z = f (z, x) → y. In such a way, the optimal prediction of a NAR model should be the equilibrium state of its dynamics if given infinitely many iterations.
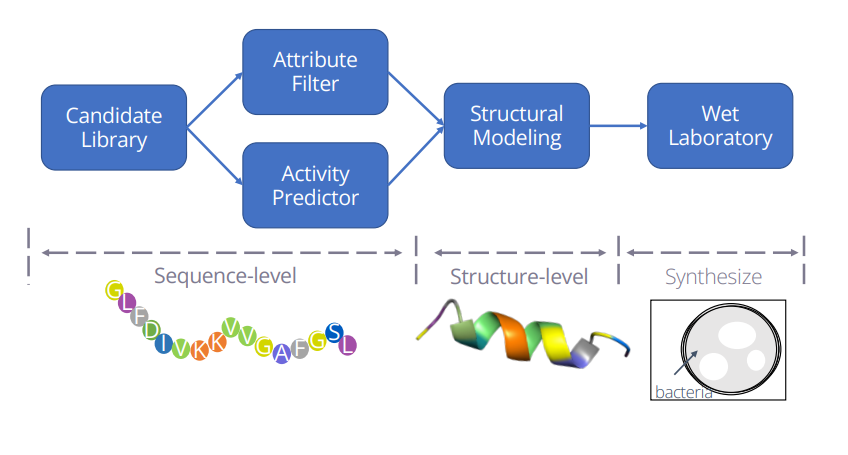
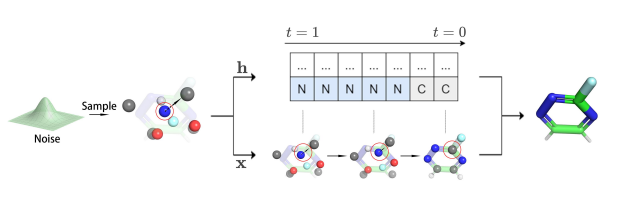
Accelerating Antimicrobial Peptide Discovery with Latent Structure
Antimicrobial peptides (AMPs) are promising therapeutic approaches against drug-resistant pathogens. Recently, deep generative models are used to discover new AMPs.
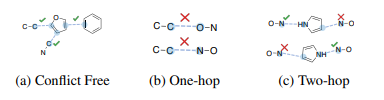
Coarse-to-Fine: a Hierarchical Diffusion Model for Molecule Generation in 3D
Generating desirable molecular structures in 3D is a fundamental problem for drug discovery. Despite the considerable progress we have achieved, existing methods usually generate molecules in atom resolution and ignore intrinsic local structures such as rings, which leads to poor quality in generated structures, especially when generating large molecules.
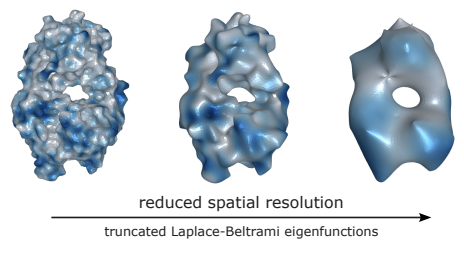
Learning Harmonic Molecular Representations on Riemannian Manifold
Molecular representation learning plays a crucial role in AI-assisted drug discovery research. Encoding 3D molecular structures through Euclidean neural networks has become the prevailing method in the geometric deep learning community.
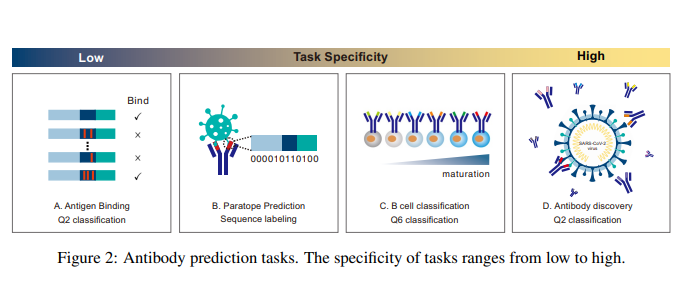
On Pre-training Language Model for Antibody
Antibodies are vital proteins offering robust protection for the human body from pathogens. The development of general protein and antibody-specific pre-trained language models both facilitate antibody prediction tasks.
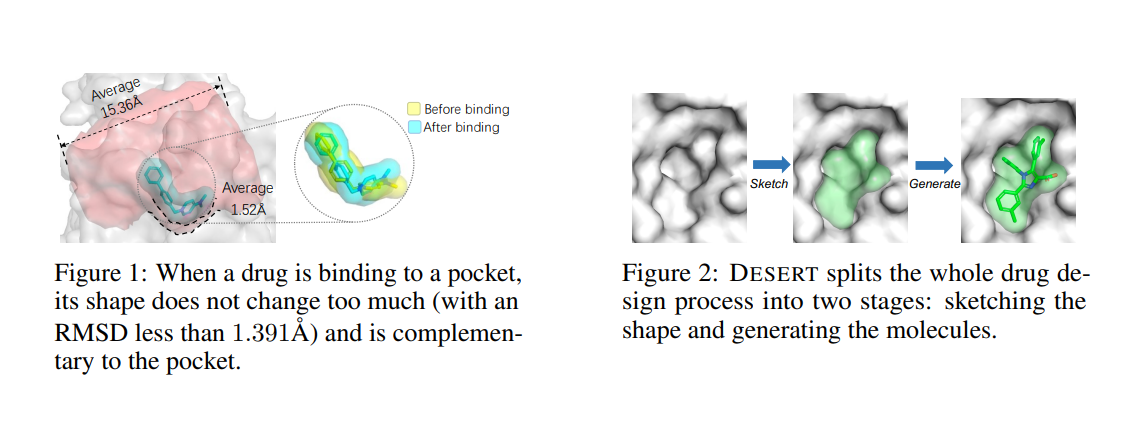
Zero-Shot 3D Drug Design by Sketching and Generating
Drug design is a crucial step in the drug discovery cycle. Recently, various deep learning-based methods design drugs by generating novel molecules from scratch, avoiding traversing large-scale drug libraries.
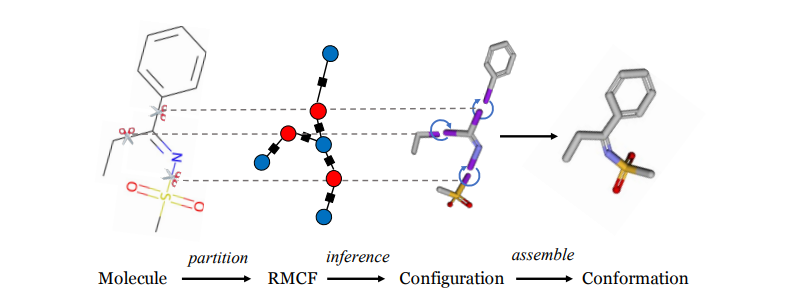
Regularized Molecular Conformation Fields
Predicting energetically favorable 3-dimensional conformations of organic molecules from molecular graph plays a fundamental role in computer-aided drug discovery research. However, effectively exploring the high-dimensional conformation space to identify (meta) stable conformers is anything but trivial.In this work, we introduce RMCF, a novel framework to generate a diverse set of low-energy molecular conformations through sampling from a regularized molecular conformation field.
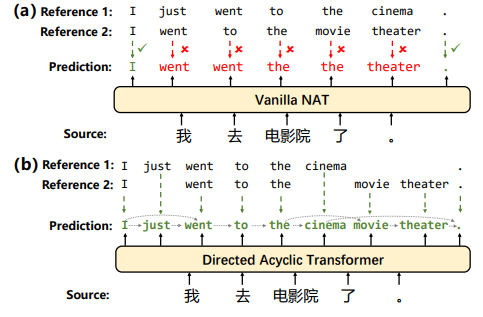
Directed Acyclic Transformer for Non-Autoregressive Machine Translation
Non-autoregressive Transformers (NATs) significantly reduce the decoding latency by generating all tokens in parallel. However, such independent predictions prevent NATs from capturing the dependencies between the tokens for generating multiple possible translations.
On the Learning of Non-Autoregressive Transformers
Non-autoregressive Transformer (NAT) is a family of text generation models, which aims to reduce the decoding latency by predicting the whole sentences in parallel. However, such latency reduction sacrifices the ability to capture left-to-right dependencies, thereby making NAT learning very challenging.
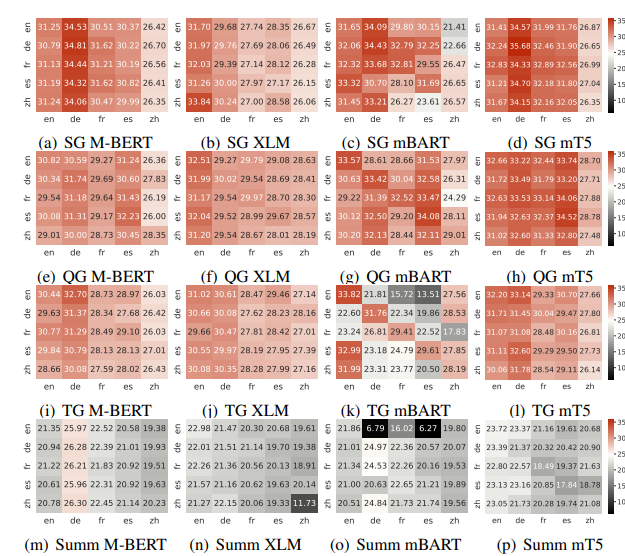
{MTG}: A Benchmark Suite for Multilingual Text Generation
We introduce MTG, a new benchmark suite for training and evaluating multilingual text generation. It is the first and largest multilingual multiway text generation benchmark with 400k human-annotated data for four generation tasks (story generation, question generation, title generation and text summarization) across five languages (English, German, French, Spanish and Chinese).
latent-{GLAT}: Glancing at Latent Variables for Parallel Text Generation
Recently, parallel text generation has received widespread attention due to its success in generation efficiency. Although many advanced techniques are proposed to improve its generation quality, they still need the help of an autoregressive model for training to overcome the one-to-many multi-modal phenomenon in the dataset, limiting their applications.
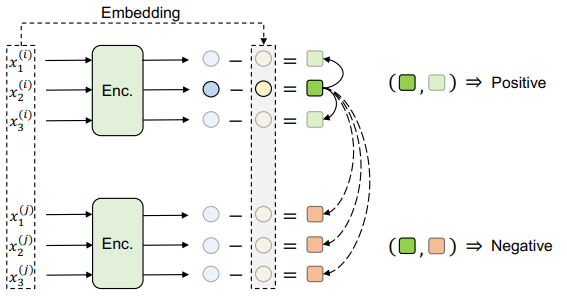
Contextual Representation Learning beyond Masked Language Modeling
How do masked language models (MLMs) such as BERT learn contextual representations? In this work, we analyze the learning dynamics of MLMs. We find that MLMs adopt sampled embeddings as anchors to estimate and inject contextual semantics to representations, which limits the efficiency and effectiveness of MLMs.
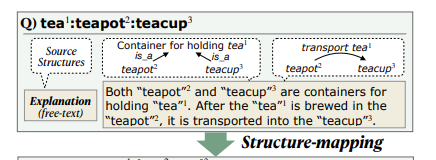
{E-KAR}: A Benchmark for Rationalizing Natural Language Analogical Reasoning
The ability to recognize analogies is fundamental to human cognition. Existing benchmarks to test word analogy do not reveal the underneath process of analogical reasoning of neural models.
Rethinking Document-level Neural Machine Translation
This paper does not aim at introducing a novel model for document-level neural machine translation. Instead, we head back to the original Transformer model and hope to answer the following question: Is the capacity of current models strong enough for document-level translation? Interestingly, we observe that the original Transformer with appropriate training techniques can achieve strong results for document translation, even with a length of 2000 words.
{switch-GLAT}: Multilingual Parallel Machine Translation via Code-switch Decoder
Multilingual machine translation aims to develop a single model for multiple language directions. However, existing multilingual models based on Transformer are limited in terms of both translation performance and inference speed.
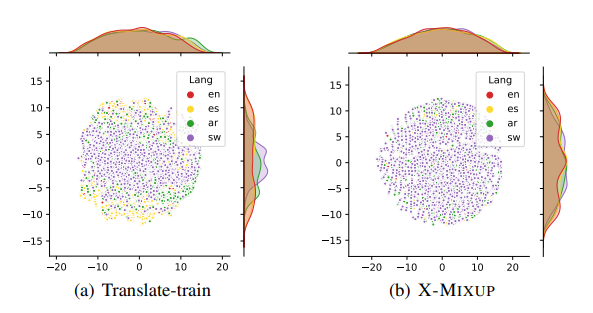
Enhancing Cross-lingual Transfer by Manifold Mixup
Based on large-scale pre-trained multilingual representations, recent cross-lingual transfer methods have achieved impressive transfer performances. However, the performance of target languages still lags far behind the source language.
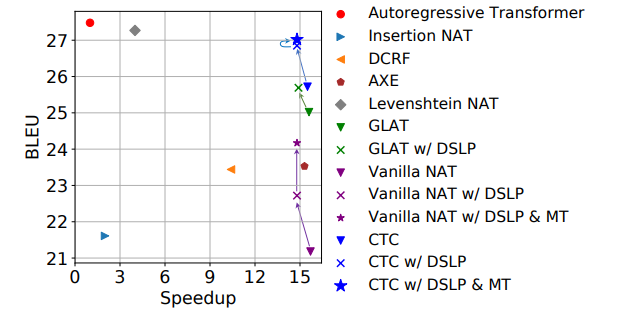
Non-Autoregressive Translation with Layer-Wise Prediction and Deep Supervision
How do we perform efficient inference while retaining high translation quality? Existing neural machine translation models, such as Transformer, achieve high performance, but they decode words one by one, which is inefficient. Recent non-autoregressive translation models speed up the inference, but their quality is still inferior.
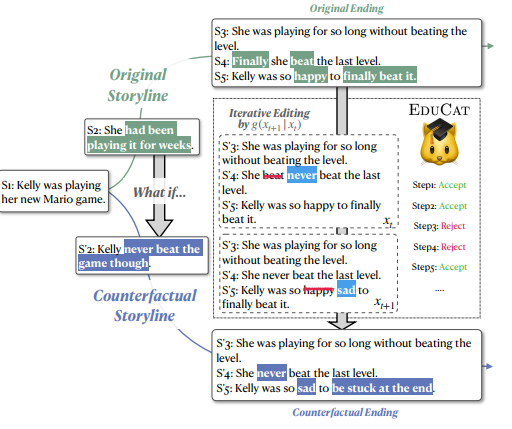
Unsupervised Editing for Counterfactual Stories
Creating what-if stories requires reasoning about prior statements and possible outcomes of the changed conditions. One can easily generate coherent endings under new conditions, but it would be challenging for current systems to do it with minimal changes to the original story.

LOREN: Logic-Regularized Reasoning for Interpretable Fact Verification
Given a natural language statement, how to verify its veracity against a large-scale textual knowledge source like Wikipedia? Most existing neural models make predictions without giving clues about which part of a false claim goes wrong. In this paper, we propose LOREN, an approach for interpretable fact verification.

Duplex Sequence-to-Sequence Learning for Reversible Machine Translation
In this work, we design a simple, direct, and fast framework for instance segmentation with strong performance. To this end, we propose a novel and effective approach, termed SOLOv2, following the principle of the SOLO method.
The {Volctrans} {GLAT} System: Non-autoregressive Translation Meets {WMT21}
This paper describes the Volctrans' submission to the WMT21 news translation shared task for German->English translation. We build a parallel (i.e., non-autoregressive) translation system using the Glancing Transformer, which enables fast and accurate parallel decoding in contrast to the currently prevailing autoregressive models.

Learning Logic Rules for Document-level Relation Extraction
Document-level relation extraction aims to identify relations between entities in a whole document. Prior efforts to capture long-range dependencies have relied heavily on implicitly powerful representations learned through (graph) neural networks, which makes the model less transparent.

{CNewSum}: A Large-scale Chinese News Summarization Dataset with Human-annotated Adequacy and Deducibility Level
Automatic text summarization aims to produce a brief but crucial summary for the input documents. Both extractive and abstractive methods have witnessed great success in English datasets in recent years.
Follow Your Path: a Progressive Method for Knowledge Distillation
Deep neural networks often have a huge number of parameters, which posts challenges in deployment in application scenarios with limited memory and computation capacity. Knowledge distillation is one approach to derive compact models from bigger ones.

Glancing Transformer for Non-Autoregressive Neural Machine Translation
Recent work on non-autoregressive neural machine translation (NAT) aims at improving the efficiency by parallel decoding without sacrificing the quality. However, existing NAT methods are either inferior to Transformer or require multiple decoding passes, leading to reduced speedup.
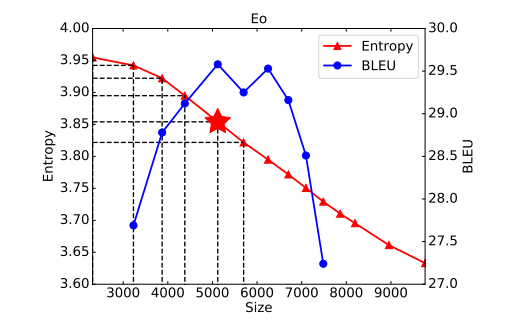
Vocabularization via Optimal Transport for Neural Machine Translation
The choice of token vocabulary affects the performance of machine translation. This paper aims to figure out what is a good vocabulary and whether one can find the optimal vocabulary without trial training.
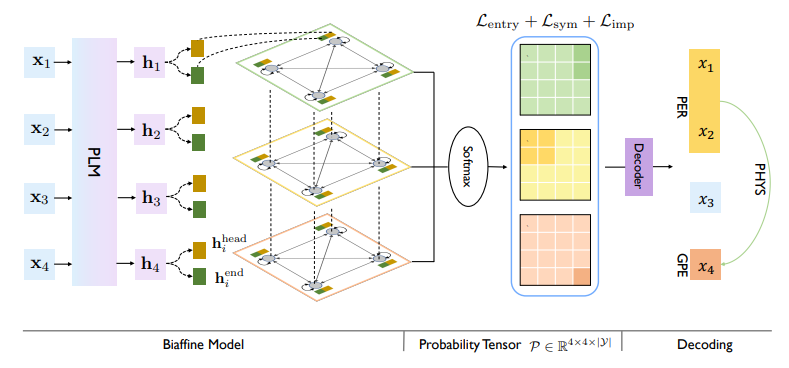
A Unified Label Space for Entity Relation Extraction
Many joint entity relation extraction models setup two separated label spaces for the two sub-tasks (i.e., entity detection and relation classification). We argue that this setting may hinder the information interaction between entities and relations.
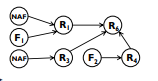
Probabilistic Graph Reasoning for Natural Proof Generation
In this paper, we investigate the problem of reasoning over natural language statements. Prior neural based approaches do not explicitly consider the inter-dependency among answers and their proofs.
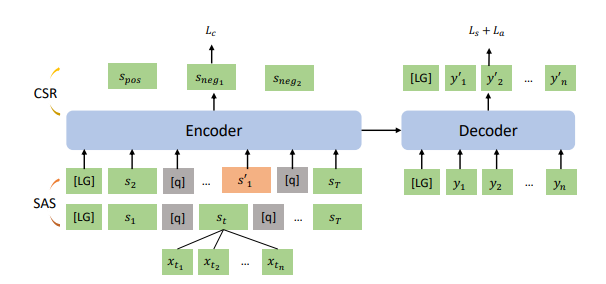
Contrastive Aligned Joint Learning for Multilingual Summarization
Multilingual text summarization requires the ability to understand documents in multiple languages and generate summaries in the corresponding language, which poses more challenges on current summarization systems. However, this problem has been rarely studied due to the lack of large-scale supervised summarization data in multiple languages.
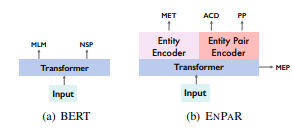
{ENPAR}: Enhancing Entity and Entity Pair Representations for Joint Entity Relation Extraction
Current state-of-the-art systems for joint entity relation extraction (Luan et al., 2019; Wad-den et al., 2019) usually adopt the multi-task learning framework. However, annotations for these additional tasks such as coreference resolution and event extraction are always equally hard (or even harder) to obtain.
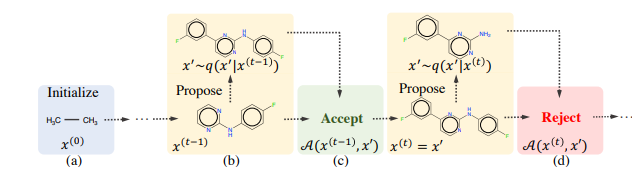
MARS: Markov Molecular Sampling for Multi-objective Drug Discovery
Searching for novel molecules with desired chemical properties is crucial in drug discovery. Existing work focuses on developing deep generative models to generate either sequences or chemical molecular graphs.
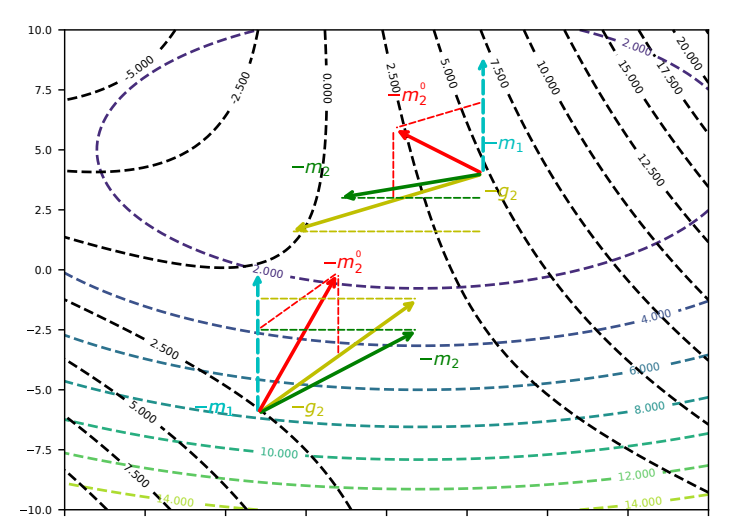
ACMo: Angle-Calibrated Moment Methods for Stochastic Optimization
Stochastic gradient descent (SGD) is a widely used method for its outstanding generalization ability and simplicity. daptive gradient methods have been proposed to further accelerate the optimization process.
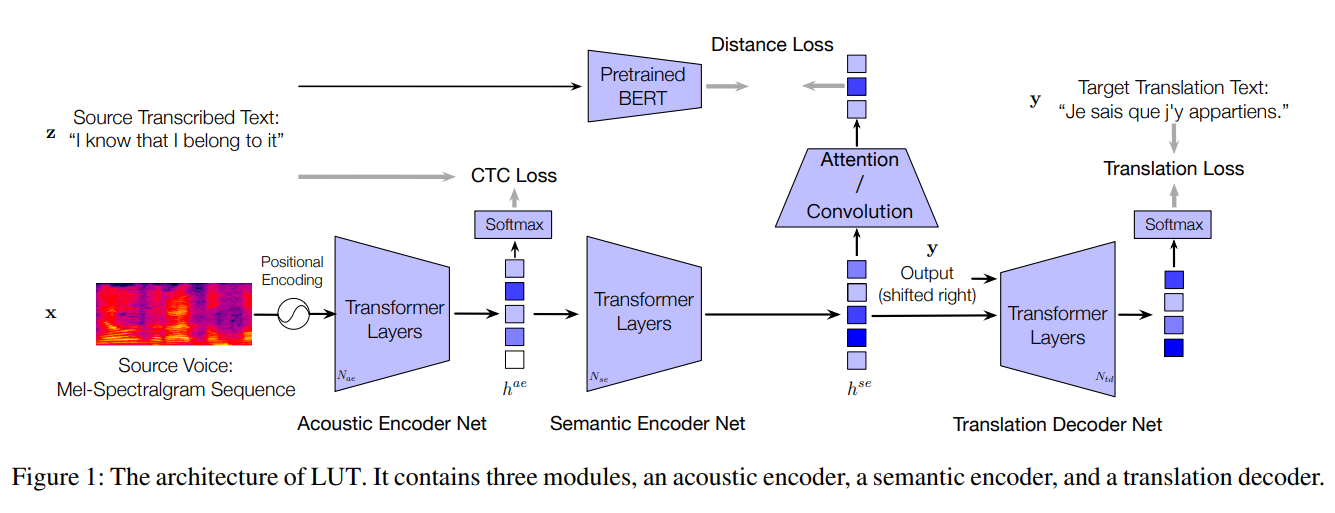
Listen, Understand and Translate: Triple Supervision Decouples End-to-end Speech-to-text Translation
An end-to-end speech-to-text translation (ST) takes audio in a source language and outputs the text in a target language. Existing methods are limited by the amount of parallel corpus.
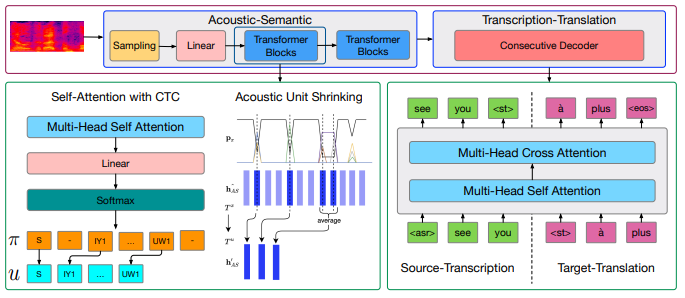
Consecutive Decoding for Speech-to-text Translation
Speech-to-text translation (ST), which directly translates the source language speech to the target language text, has attracted intensive attention recently. However, the combination of speech recognition and machine translation in a single model poses a heavy burden on the direct cross-modal cross-lingual mapping.
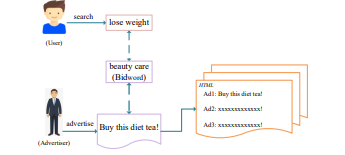
Triangular Bidword Generation for Sponsored Search Auction
Sponsored search auction is a crucial component of modern search engines. It requires a set of candidate bidwords that advertisers can place bids on.
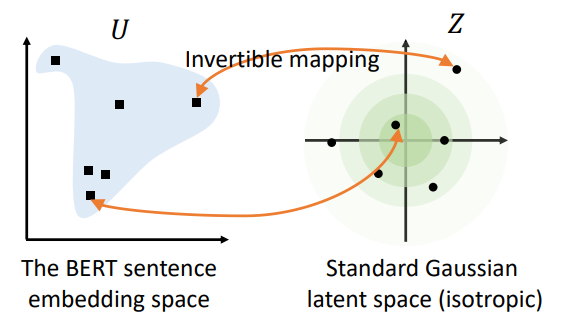
On the Sentence Embeddings from Pre-trained Language Models
Pre-trained contextual representations like BERT have achieved great success in natural language processing. However, the sentence embeddings from the pre-trained language models without fine-tuning have been found to poorly capture semantic meaning of sentences.
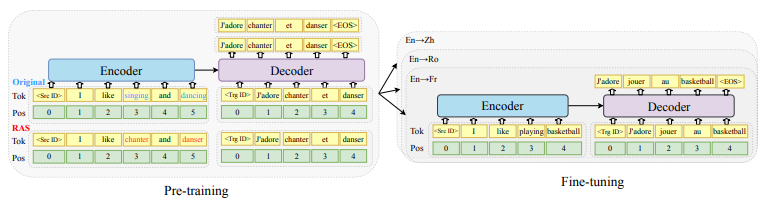
Pre-training Multilingual Neural Machine Translation by Leveraging Alignment Information
We investigate the following question for machine translation (MT): can we develop a single universal MT model to serve as the common seed and obtain derivative and improved models on arbitrary language pairs? We propose mRASP, an approach to pre-train a universal multilingual neural machine translation model. Our key idea in mRASP is its novel technique of random aligned substitution, which brings words and phrases with simlar meanings across multiple languages closer in the representation space.
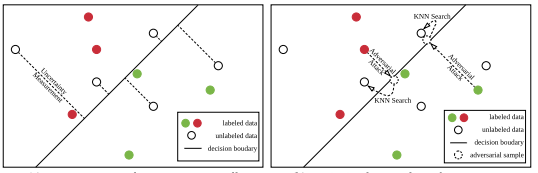
Active Sentence Learning by Adversarial Uncertainty Sampling in Discrete Space
Active learning for sentence understanding aims at discovering informative unlabeled data for annotation and therefore reducing the demand for labeled data. We argue that the typical uncertainty sampling method for active learning is time-consuming and can hardly work in real-time, which may lead to ineffective sample selection.
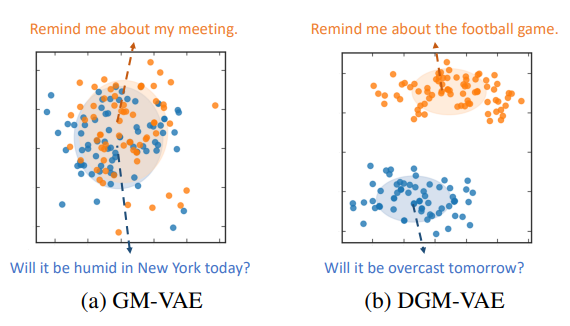
Dispersing Exponential Family Mixture {VAE}s for Interpretable Text Generation
Deep generative models are commonly used for generating images and text. Interpretability of these models is one important pursuit, other than the generation quality.

{QuAChIE}: Question Answering based {Chinese} Information Extraction System
In this paper, we present the design of QuAChIE, a Question Answering based Chinese Information Extraction system. QuAChIE mainly depends on a well-trained question answering model to extract high-quality triples.
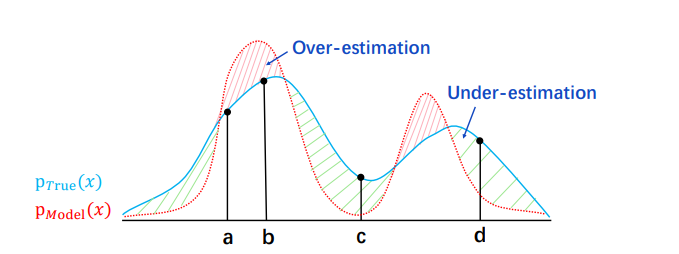
Do you have the right scissors? Tailoring Pre-trained Language Models via {Monte}-{Carlo} Methods
It has been a common approach to pre-train a language model on a large corpus and fine-tune it on task-specific data. In practice, we observe that fine-tuning a pre-trained model on a small dataset may lead to over- and/or under-estimation problem.
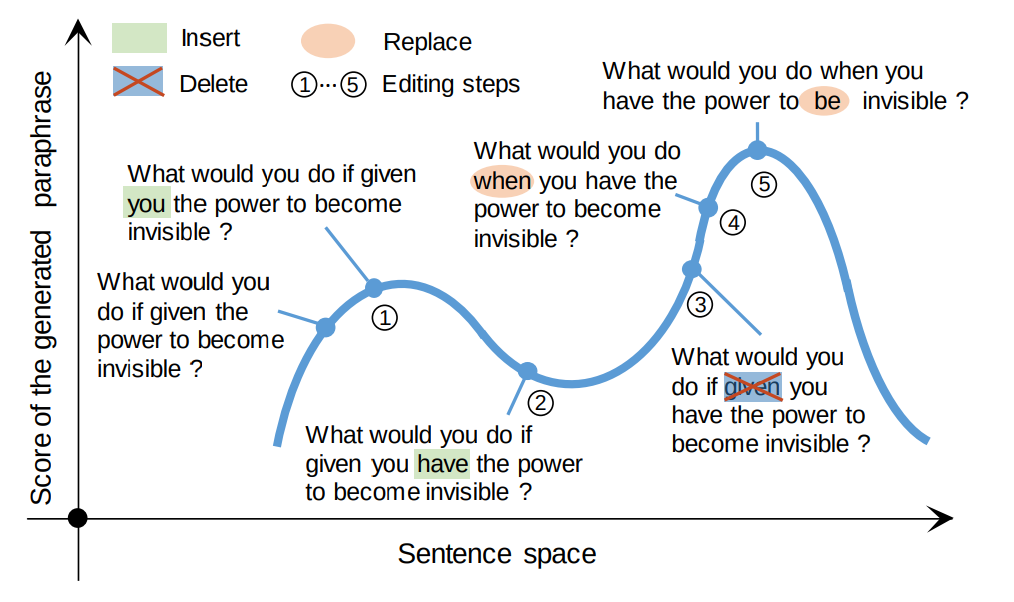
Unsupervised Paraphrasing by Simulated Annealing
Unsupervised paraphrase generation is a promising and important research topic in natural language processing. We propose UPSA, a novel approach that accomplishes Unsupervised Paraphrasing by Simulated Annealing.
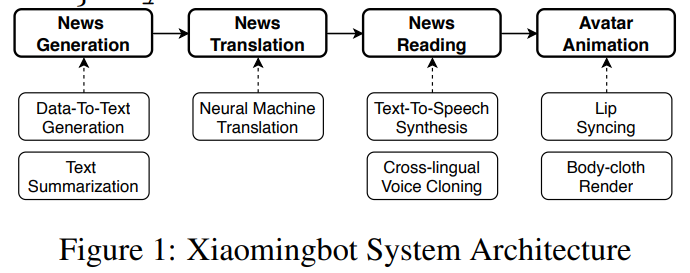
Xiaomingbot: A Multilingual Robot News Reporter
This paper proposes the building of Xiaomingbot, an intelligent, multilingual and multi-modal software robot equipped with four integral capabilities: news generation, news translation, news reading and avatar animation. Its system summarizes Chinese news that it automatically generates from data tables.
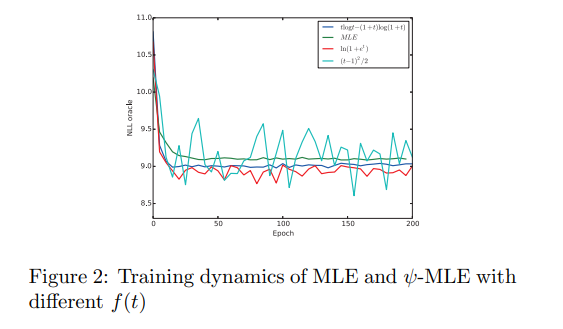
Improving Maximum Likelihood Training for Text Generation with Density Ratio Estimation
Auto-regressive sequence generative models trained by Maximum Likelihood Estimation suffer the exposure bias problem in practical finite sample scenarios. The crux is that the number of training samples for Maximum Likelihood Estimation is usually limited and the input data distributions are different at training and inference stages.
Variational Template Machine for Data-to-Text Generation
How to generate descriptions from structured data organized in tables? Existing approaches using neural encoder-decoder models often suffer from lacking diversity. We claim that an open set of templates is crucial for enriching the phrase constructions and realizing varied generations.Learning such templates is prohibitive since it often requires a large paired
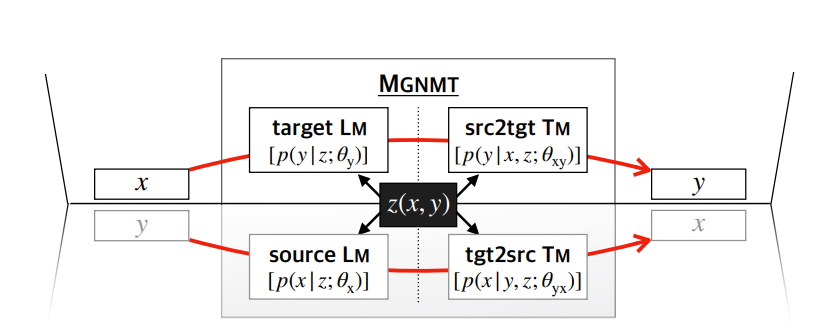
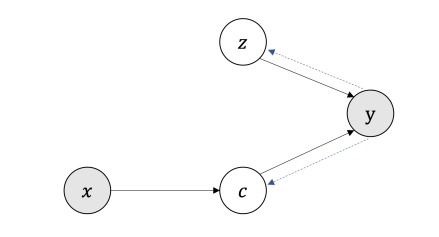
Mirror Generative Models for Neural Machine Translation
Training neural machine translation models (NMT) requires a large amount of parallel corpus, which is scarce for many language pairs. However, raw non-parallel corpora are often easy to obtain.
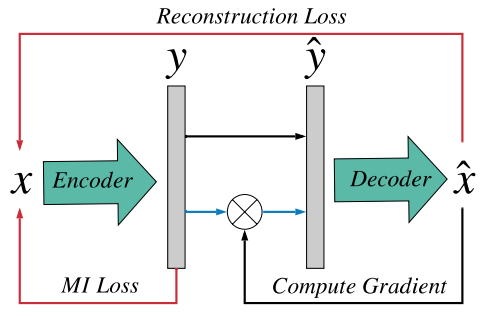
Infomax Neural Joint Source-Channel Coding via Adversarial Bit Flip
Although Shannon theory states that it is asymptotically optimal to separate the source and channel coding as two independent processes, in many practical communication scenarios this decomposition is limited by the finite bit-length and computational power for decoding. Recently, neural joint source-channel coding (NECST) is proposed to sidestep this problem.

Towards Making the Most of {BERT} in Neural Machine Translation
GPT-2 and BERT demonstrate the effectiveness of using pretrained language models (LMs) on various natural language processing tasks. However, LM fine-tuning often suffers from catastrophic forgetting when applied to resource-rich tasks.
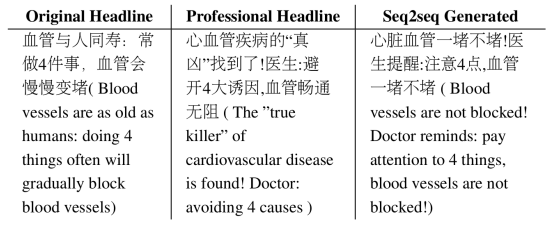
Importance-Aware Learning for Neural Headline Editing
Many social media news writers are not professionally trained. Therefore, social media platforms have to hire professional editors to adjust amateur headlines to attract more readers.

Rethinking Text Attribute Transfer: A Lexical Analysis
Text attribute transfer is modifying certain linguistic attributes (e.g. sentiment, style, authorship, etc.) of a sentence and transforming them from one type to another.
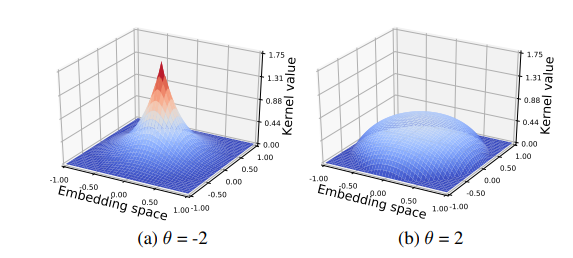
Kernelized {Bayesian} Softmax for Text Generation
Neural models for text generation require a softmax layer with proper word embeddings during the decoding phase. Most existing approaches adopt single point embedding for each word.

Dynamically Fused Graph Network for Multi-hop Reasoning
Text-based question answering (TBQA) has been studied extensively in recent years. Most existing approaches focus on finding the answer to a question within a single paragraph.

Generating Fluent Adversarial Examples for Natural Languages
Efficiently building an adversarial attacker fornatural language processing (NLP) tasks is areal challenge. Firstly, as the sentence spaceis discrete, it is difficult to make small perturbations along the direction of gradients.
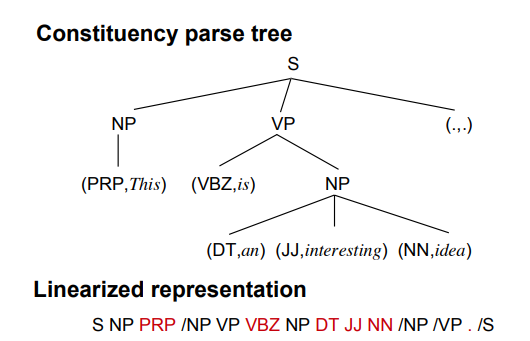
Generating Sentences from Disentangled Syntactic and Semantic Spaces
Variational auto-encoders (VAEs) are widely used in natural language generation due to the regularization of the latent space. However, generating sentences from the continuous latent space does not explicitly model the syntactic information.
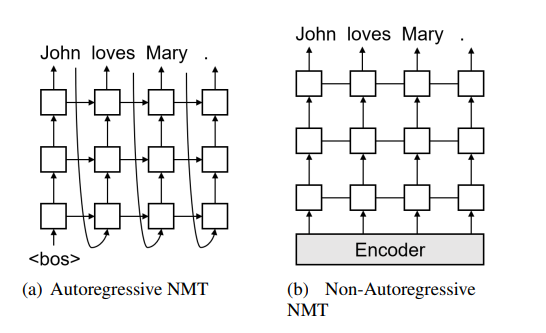
Imitation Learning for Non-Autoregressive Neural Machine Translation
Non-autoregressive translation models (NAT) have achieved impressive inference speedup. A potential issue of the existing NAT algorithms, however, is that the decoding is conducted in parallel, without directly considering previous context.
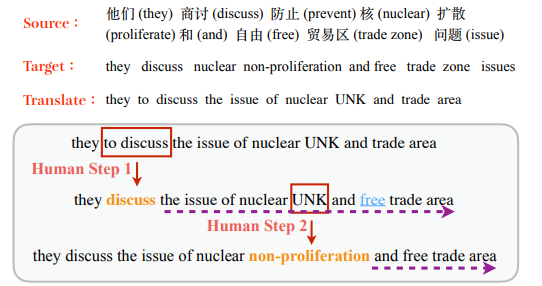
Correct-and-Memorize: Learning to Translate from Interactive Revisions
State-of-the-art machine translation models are stillnot on a par with human translators. Previous worktakes human interactions into the neural machine translation process to obtain improved results in target languages.
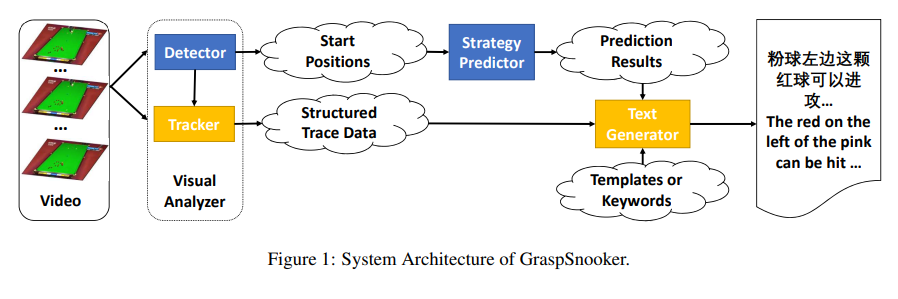
{GraspSnooker}: Automatic {Chinese} Commentary Generation for Snooker Videos
We demonstrate a web-based software system, GraspSnooker, which is able to automatically generate Chinese text commentaries for snooker game videos. It consists of a video analyzer, a strategy predictor and a commentary generator.
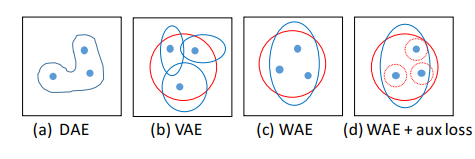
Stochastic {W}asserstein Autoencoder for Probabilistic Sentence Generation
The variational autoencoder (VAE) imposes a probabilistic distribution (typically Gaussian) on the latent space and penalizes the Kullback-Leibler (KL) divergence between the posterior and prior. In NLP, VAEs are extremely difficult to train due to the problem of KL collapsing to zero.

Why do neural dialog systems generate short and meaningless replies? a comparison between dialog and translation
This paper addresses the question: Why do neural dialog systems generate short and meaningless replies? We conjecture that, in a dialog system, an utterance may have multiple equally plausible replies, causing the deficiency of neural networks in the dialog application. We propose a systematic way to mimic the dialog scenario in a machine translation system, and manage to reproduce the phenomenon of generating short and less meaningful sentences in the translation setting, showing evidence of our conjecture..

CGMH: Constrained sentence generation by metropolis-hastings sampling
In real-world applications of natural language generation, there are often constraints on the target sentences in addition to fluency and naturalness requirements. Existing language generation techniques are usually based on recurrent neural networks (RNNs).
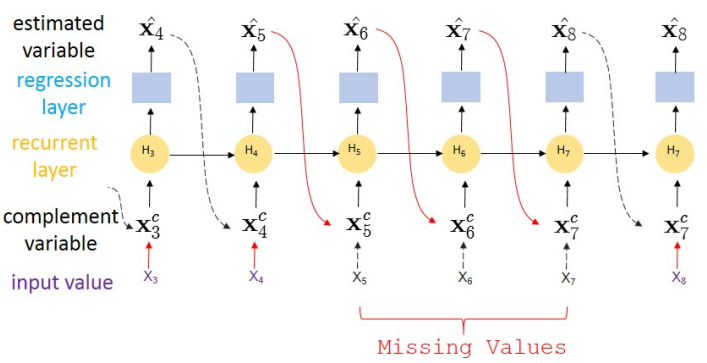
BRITS: Bidirectional Recurrent Imputation for Time Series
Time series are widely used as signals in many classification/regression tasks. It is ubiquitous that time series contains many missing values.

On Tree-Based Neural Sentence Modeling
Neural networks with tree-based sentence encoders have shown better results on many downstream tasks. Most of existing tree-based encoders adopt syntactic parsing trees as the explicit structure prior.

Modeling Past and Future for Neural Machine Translation
Existing neural machine translation systems do not explicitly model what has been translated and what has not during the decoding phase. To address this problem, we propose a novel mechanism that separates the source information into two parts: translated Past contents and untranslated Future contents, which are modeled by two additional recurrent layers.
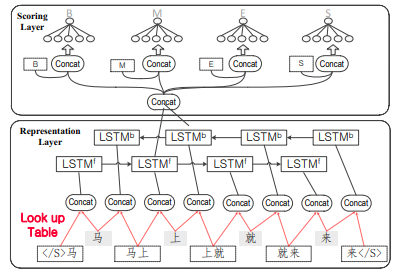
Word-Context Character Embeddings for {C}hinese Word Segmentation
Neural parsers have benefited from automatically labeled data via dependency-context word embeddings. We investigate training character embeddings on a word-based context in a similar way, showing that the simple method improves state-of-the-art neural word segmentation models significantly, beating tri-training baselines for leveraging auto-segmented data..
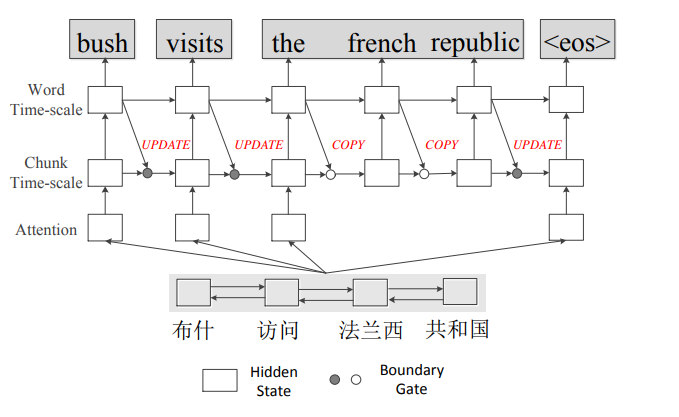
Chunk-Based Bi-Scale Decoder for Neural Machine Translation
In typical neural machine translation (NMT), the decoder generates a sentence word by word, packing all linguistic granularities in the same time-scale of RNN. In this paper, we propose a new type of decoder for NMT, which splits the decode state into two parts and updates them in two different time-scales.
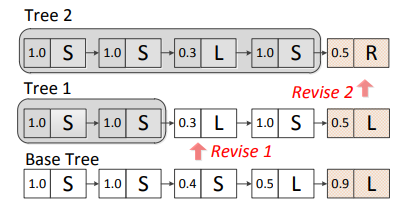
A Search-Based Dynamic Reranking Model for Dependency Parsing
We propose a novel reranking method to extend a deterministic neural dependency parser. Different to conventional k-best reranking, the proposed model integrates search and learning by utilizing a dynamic action revising process, using the reranking model to guide modification for the base outputs and to rerank the candidates.
Evaluating a Deterministic Shift-Reduce Neural Parser for Constituent Parsing
Greedy transition-based parsers are appealing for their very fast speed, with reasonably high accuracies. In this paper, we build a fast shift-reduce neural constituent parser by using a neural network to make local decisions.
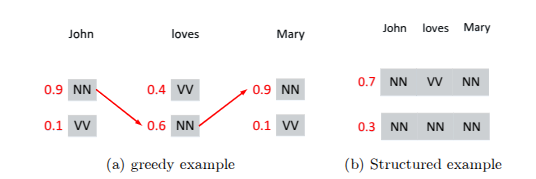
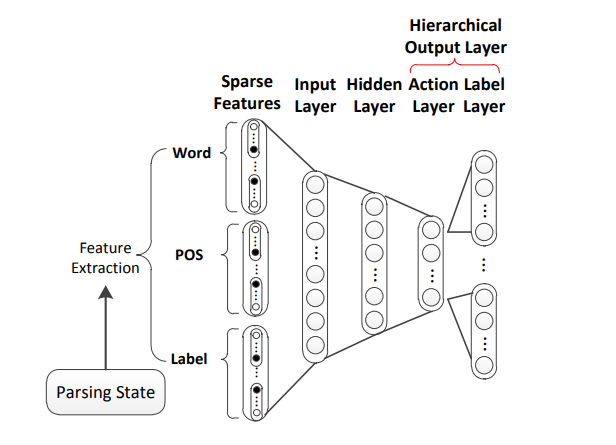
A Neural Probabilistic Structured-Prediction Method for Transition-Based Natural Language Processing
We propose a neural probabilistic structured-prediction method for transition-based natural language processing, which integrates beam search and contrastive learning. The method uses a global optimization model, which can leverage arbitrary features over non-local context.
Enhancing Shift-Reduce Constituent Parsing with Action N-Gram Model
Current shift-reduce parsers “understand” the context by embodying a large number of binary indicator features with a discriminative model. In this article, we propose the action n-gram model, which utilizes the action sequence to help parsing disambiguation.
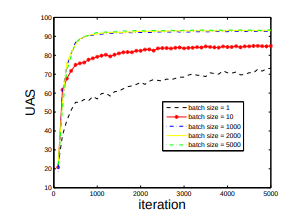
A Neural Probabilistic Structured-Prediction Model for Transition-Based Dependency Parsing
Neural probabilistic parsers are attractive for their capability of automatic feature combination and small data sizes. A transition-based greedy neural parser has given better accuracies over its linear counterpart.




